Image Spam
Hunter
Yan Gao, Ming Yang and Xiaonan Zhao
EECS
Department, Northwestern University
y-gao2,m-yang4,xiaonan-zhao@northwestern.edu
Machine
Learning Course Project
Advisor:
Professor Bryan Pardo
Quick links: Motivation Solution Dataset Evaluation Software
Report
Reference
Anti-spam
is a very active area of research, and various forms of filters, such as
white-lists, black-lists, and content-based lists are widely used to defend
against spam. Content-based filters make estimations of spam likelihood based
on the text of that email message and filter messages based on a pre-selected
threshold [2]. Since spam detection can be converted into
the problem of text classification, many content-based filters utilize
machine-learning algorithms for filtering spam. However, a number of spammers
have been evading filters recently by encoding their messages as images and
including some meaningless good words. This implies the contents are hard to
retrieve from the binary image encoding.
This
type of image spam is not rare anymore and accounts for 30% of all global spam
in 2006, compared with just 1% in late 2005. By sending e-mails that contain no
text, only pictures, or along with meaningless good words, scammers have found
that they can evade many security systems. The messages often include image
files that have a screen shot offering the same types of information advertised
in more traditional text-based spam. Spammers are also getting sneakier, using
techniques like image tiling to vary the images slightly for each message. They
do this easily by changing the shade of the border or background, changing the
line spacing or margins, or even adding tiny specks to the background. These
changes are unnoticeable to the eyes, but completely change the data appearing
to most anti-spam engines. The consequence is a huge quantity of image-based
spam that contains random patterns with almost no repetitions. Some sample spam
images are shown in Fig.1 to Fig. 5 to illustrate the diversity of spam images.


Figure1. Changing the color of
background


Figure2. Inclining the main content
of the images


Figure3. Changing the line spaces
and margins

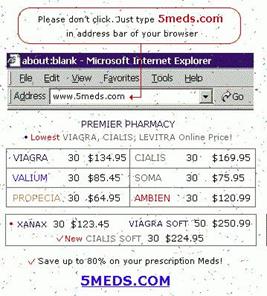
Figure4. Adding tiny specks to the
background, and changing some content of the images
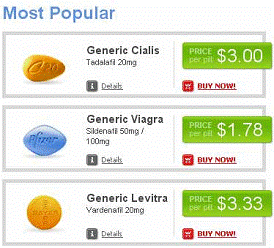
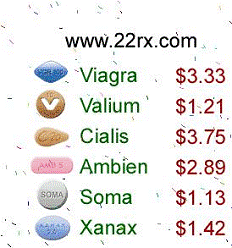
Figure5. Image spams
with icons
In
this project, we aim to explore recurrent pattern detection system against
image-based spam by using machine learning methods. We aim to find an intrinsic
mechanism to match recurrent patterns across similar but not-identical images.
In the real internet, mail service providers, e.g. hotmail and gmail, can provide the customers a ``Junk`` button, which may help
them to collect useless spam emails and further filter out huge number of
similar spams received by other customers. It is an
important feature that spam email detection system can tolerate some false negatives
(i.e. allowing some spams to get in), but can not
accept the false
positives (i.e. filtering off the normal photos and image
attachments).
To
simulate the real spam detection process in the internet, in this project, we
propose a learning-based prototype system ``Image Spam Hunter`` to
differentiate spam images from normal photos. We first cluster the collected
disordered spams into hierarchical groups based on
image similarity measurement, such as k-means or normalized cuts [6]
by using hierarchical color and gradient orientation histogram [3].
As a result, we can automatically obtain many groups of training spam images.
Second, since the spam images are artificially generated, we expect their image
texture statistics are distinguishable from natural images such as sky,
mountain, beach, buildings, and human. Therefore, we propose to employ a recent
machine learning algorithm, probabilistic boosting tree (PBT) [7], to distinguish image spams from good emails with image attachment. The proposed
method achieves 0.86% false positive rates versus 10% false negative rates in
5-fold cross-validation in a database with 928 spam images and 810 normal photos.
1) Image Feature Extraction
We
consider two feature vectors for learning, color histogram and gradient
orientation histogram. The observation is that most of spam images are
converted from text spams, although they may contain some
icons and artifacts. Thus, the color components may be quite limited compared
with natural scenes. As shown in Fig.6, the color histograms of natural scenes
tend to be continuous, while the color histogram of artificial spam image tends
to have some isolated peeks. Another observation is that the distribution of
gradient orientation may reveal the characteristics of texts. Fig.7 illustrates
the comparison of 1D histogram of image gradient orientation of spam images and
natural images. The distributions of gradient orientation for natural images
appear more uniform and noisy than those of spam images. Gradient orientation
histogram is particular effective to deal with gray-level images.

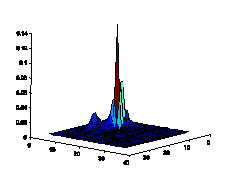

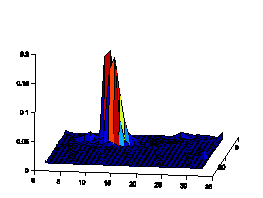
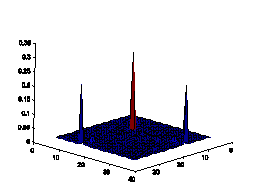
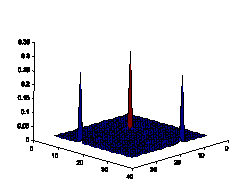
Figure6. Color histograms comparison
of natural images and spam images in 32*32 2D normalized RG plane

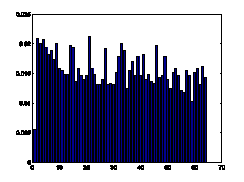

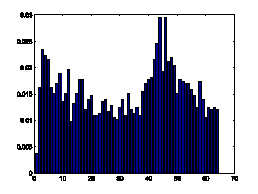

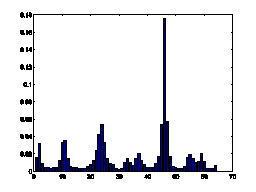

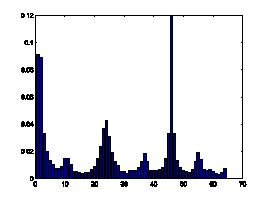
Figure7. Gradient orientation
histograms comparison of natural images and spam images
2) Training Set Generation
Since
there are several different classes of spam images, e.g. spams
with texts and artifacts or spams with icons, the
spam images in the same class appear very similar in feature spaces but quite
different from other classes. To avoid only selecting specific groups of spam
images in the training set, we need a rough clustering to generate the training
set for probabilistic boosting tree learning rather than pure random selection.
3) Probabilistic Boosting Tree (PBT)
Classification
Measure
image similarity is an active and open research topic which is generally very
difficult. In this project, we aim to distinguish a specific group, i.e. the
spam images, from normal photos by inductive supervised learning. Thus, we
collect training spam and normal images samples Ii and
represent them as feature vectors with labels (![]() ), where yi=+1 indicates spam
image and yi =-1 for normal images.
), where yi=+1 indicates spam
image and yi =-1 for normal images.
We
implement a light version of probabilistic boosting tree (PBT) method to
classify the spam images and natural images. Essentially, PBT is a decision
tree trained with positive (spam images) and negative (normal images) samples,
where each node in the tree is an Adaboost
classifier. For more details about PBT, please refer to our final report.
We
collected 928 spam images from real spam emails as the spam sample set. These
images are subset of image spams we received in the
last 6 months where image spams with animation are
excluded. The normal images set include 810 image randomly downloaded from Flickr.com
along with 20 scanned documents. The spam dataset is available here, while
the normal image dataset is available here.
We
employ normalized RG planes as the color space which is insensitive to
lightings (we also tested Hue-Saturation planes, the performance is similar).
The color histograms are sorted in decreasing order and truncated to keep top D
(e.g. 64 or 128) bins. In our PBT implementation, we employ Gentle Adaboost classifier in OpenCV [4] library at each node which consists of 100 decision stumps
as weak classifiers. ε is set to
0.1 to divide the tree.
We
test the spam detection results by 5-fold cross-validation on the database with
928 spam images and 810 natural images. There is no overlap between the
training and testing samples. The performance is measured with the average
false positive (FP) rate, i.e. the misclassification rate of normal images, and
true positive (TP) rate, i.e. the detection rate of spam images, as follows:
![]() ;
; ![]() .
.
By
testing different D values as in Table1, we find D=64 is
sufficient to detect the spams in our current sample set
(classification accuracies over both training spam and normal image are listed
reference). By varying the δ, we obtain the Receiver Operating Characteristic
(ROC) curve for D=64 feature vectors as shown in Fig.8. Without learning
method, the expectation of random guess will generate a 45o line in
the ROC curve. From the curve, we can see our approach achieves 89.44%
detection rate of spams at FP rate 0.86%. We show
more analysis in final report.
|
|
Accuracy |
FP Rate |
TP Rate |
|
32D |
0.5631 |
0.0136 |
0.1944 |
|
64D |
0.9494 |
0.0420 |
0.9417 |
|
128D |
0.9471 |
0.0469 |
0.9426 |
Table1. Comparison of 5-fold cross-validation
performance of different D dimensional vectors
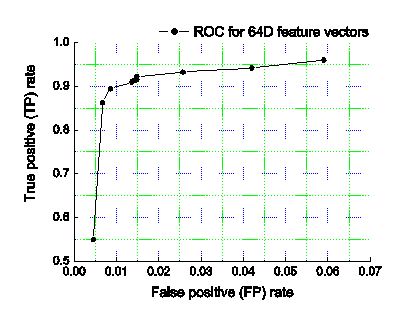
Figure8. ROC curve for 64D feature vectors
We
develop an interface for spam hunter (as shown in Fig.9),
if you are interested in it, please download the package from here.
Figure9. Software interface
For
more details about this project, please refer to our final report here.
[1] J. Blosser and D. Josephsen.
Scalable centralized bayesian spam mitigation with bogofilter. In Proc. USENIX LISA, 2004.
[2] K. Li and Z. Zhong. Fast
statistical spam filter by approximate classifications. In ACM SIGMETRICS, pages 347 - 358,
[3] A. Maccato and R. deFigueiredo. The image gradient histogram and associated orientation signatures. In IEEE International Symposium on Circuits and Systems, volume 1, pages 239-242,
[4] Open Source Computer Vision Library. http://www.intel.com/technology/computing/opencv/.
[5] SA. http://spamassassin.apache.org/.
[6] J. Shi and J. Malik. Normalized cuts and image segmentation.
In IEEE Transactions on Pattern Analysis
and Machine Intelligence, volume 22,
pages 888-905, 2000.
[7] Z. Tu. Probabilistic boosting-tree: Learning discriminative
models for classification, recognition, and clustering. In IEEE International Conf.
on ComputerVision (ICCV'05), volume 2,
pages 1589-1596,