research
This page was last updated in August 2012 - visit my more up-to-date page: http://sites.google.com/site/scottfriedmanresearch/.
Here is where I discuss several of my research interests in broad detail. For more detail on my contributions to date, please see the publications page.
learning and representing causal models
David Hume wrote about causality, "it is custom which rules." When people encounter the same phenomenon as few as two times, we find similarities and create descriptive mental models of what-follows-what. Statisticial approaches, such as hierarchical Bayesian models, can effectiely approximate how humans learn the form and structure of causal relationships between discrete events. Similarly, analogical learning approaches have been shown to learn descriptive causal models from very few examples. These statistical, descriptive causal models are important starting points for a deeper understanding of the world: knowledge of processes and mechanisms.
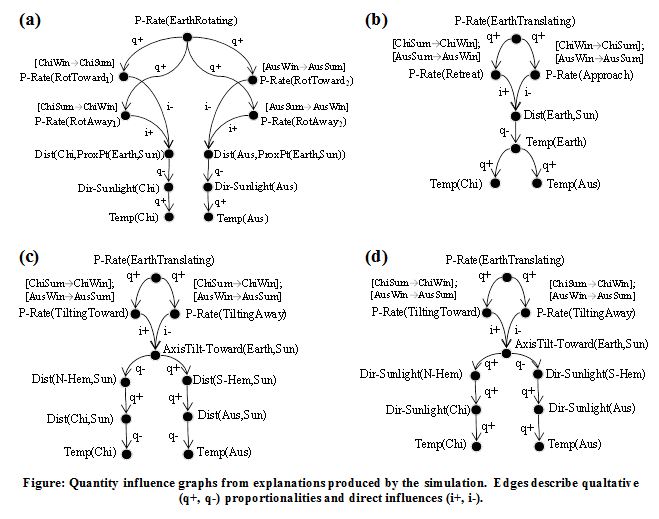
My research systems generate descriptive as well as mechanism-based causal models. These two types of models influence and constrain each other. For instance, Kepler's descriptive model of planetary revolution provided the groundwork for the Newton's mechanism-based model. For examples of qualitative mechanism-based models, see the four influence graphs below, which describe processes and causal relationships between quantities. Graphs (a-c) simulate three misconceptions about the changing of the seasons; graph (d) simulates a slightly-simplified scientifically-correct model. These were generated automatically using abductive and qualitative reasoning for a cognitive modeling simulation. For more detail, visit the publications page.
conceptual change
Certain knowledge-oriented actions that are natural for people are surprisingly difficult for machines to accomplish easily. For instance, given new information, people can decide to ignore it, discredit it, believe it partially/skeptically, or believe it entirely. On larger timescales, people undergo conceptual change, where their ontology and beliefs evolve over time with experience and instruction. This requires, at the very least, entertaining contradictory beliefs and determining which is more credible or productive.
Current AI systems use logical belief revision, large probability distributions, or Truth Maintenance Systems to maintain consistency in their knowledge. These approaches involve different biases for deciding what (and what not) to believe. None of these approaches alone has modeled human-scale conceptual change. I believe that hybrid approaches that track the justification for beliefs, the source of beliefs, and the statistical productivity of beliefs are the most promising for achieving computational conceptual change.

The above figure shows a small portion of an explanation-based network used in my research for modeling conceptual change. It contains propositional beliefs and qualitative model fragments in its domain knowledge (bottom tier) which is related via TMS justification structure (middle tier). Well-founded TMS support is aggregated as explanations (top tier). As new knowledge is encountered, additional support is computed for previous beliefs, so the system can incrementally transition between mutually inconsistent theories and representations. As discussed in the publications, this permits the agent to:
- Estimate the computation required to transition between beliefs.
- Allow beliefs to compete for productivity in explanations.
- Evaluate explanations using numerical cost functions to determine which best supports an obervation, e.g. for abductive reasoning.
- Reason with inconsistent domain knowledge, provided individual explanations are consistent.