Final Project
Design Proposal
Forrest Sondahl
Multi-Agent
Modeling (2005)
Summary:
I plan to design a framework for doing genetic
programming in the NetLogo language, and then use this framework
to create two different models. When I speak of genetic
programming, I do not mean modeling the genetic or evolutionary
processes that occur in nature. Rather, I am referring to the
technique known as genetic programming that lies entirely within the
domain of computer science.
|
Definition:
Genetic programming
- (GP) A programming technique which extends the genetic
algorithm to the domain of whole computer programs. In
GP, populations of programs are genetically bred to solve
problems. Genetic programming can solve problems of system
identification, classification, control, robotics, optimization,
game playing, and pattern recognition. Starting with a
primordial ooze of hundreds or thousands of randomly created
programs composed of functions and terminals appropriate to the
problem, the population is progressively evolved over a series of
generations by applying the operations of Darwinian fitness
proportionate reproduction and crossover (sexual recombination).
( http://www.dictionary.com
)
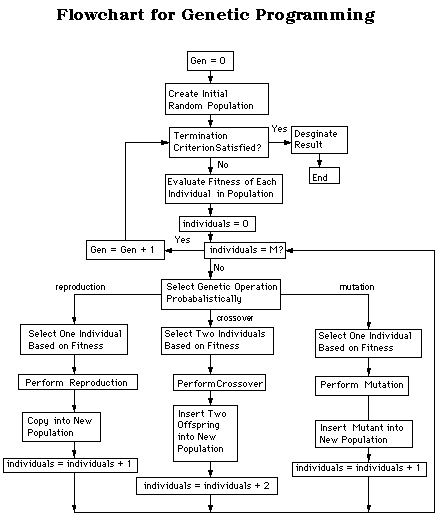
(Chart courtesy of the tutorial
at
http://www.geneticprogramming.com/,
which is recommended reading for an overview of genetic
programming.)
|
|
Genetic programming is an intriguing field for many
reasons. It is a case of a computer program writing computer
programs. Genetic programming can also demonstrate the power of
the Darwinian principles of evolution, even beyond the bounds of
biology. The primary goal is to provide a demonstration how
genetic programming works, on a visual and interactive level.
The secondary goal is to leave behind a code framework for genetic
programming that could be adapted to different problems without great
difficulty by future NetLogo modelers.
Educational Benefits:
As noted just above, I think genetic programming is an
intriguing topic. Therefore it is not too surprising that I
believe it would be beneficial for more people to know about it, and
understand how it works. Obviously, the models I will be
developing could be useful to run in a computer science class such as
Introduction to Artificial Intelligence. Furthermore, I
suggest, that the although the details of implementing genetic
programming might be a bit difficult for the lay person to digest,
the general procedure is quite accessible to the general public.
I suspect that biologists in particular would be interested to see
this "artificial evolution" at work. It is also
possible to make the case that genetic programming could provide
insight into the way that intelligence has evolved in the biological
world -- and that our minds (and the minds of animals) could be
conceived of as highly sophisticated computer programs that have
evolved over time, with some implicit "fitness function" of
survival and capacity to reproduce (as opposed to the explicitly
formulated fitness functions found in genetic programming).
Before stepping too far in that direction, however, it must be
recalled that the genetic programming method was created not in an
attempt to model how intelligent life formed in the past, but rather
as a tool for how to create intelligent behavior in computer programs
in the present. Regardless of debate around the applicability
of the process to historical evolution, the mere act of engaging in
comparison and contrast between the biological evolution of creatures
and the simulated evolution of computer programs is an educational
process. For this reason, I hope that the models will make
their way beyond the boundaries of their parent discipline, computer
science. Also, the realization that it is possible for computer
programs to create computer programs is mind-expanding, for those who
have not encountered it before.
I will first discuss general
issues of implementing genetic programming in NetLogo, and then
comment briefly on the two models that I will be building.
Implementation and Rationale:
Overall, I am expecting the implementation to be rather
involved, and probably downright tricky. For the present,
therefore, this section will consist of a fair amount of guesswork,
as well as meandering thought processes weighing the pros and cons of
various implementation choices. At least some design choices
seem relatively straightforward--each computer program will be
represented in a given generation by an agent of breed "codeturtle".
Setup Phase:
Every genetic programming simulation
is a search for an algorithm which solves some given problem.
This problem statement will be represented by some combination of
patches and agents and various logic associated with them. The
problem will also impose certain restrictions on which actions a
codeturtle may perform.
It will also be necessary to
choose a list of functions (commands, reporters, control structures,
and operators) and terminals (numbers, variables, slider-variables)
which will make up the DNA of the programs the represent. These
ingredients should be different for each problem, and so we need to
be able to specify them in a fairly flexible way. It is
probably good enough to represent the terminals as a flat list, which
may be chosen from at random to build expressions. However, the
functions each require their own syntax (especially in the number and
type of arguments). I haven't figured out exactly how I want to
treat this yet. In any case, the last step of setup is to
create a population of codeturtles which contain randomly generated
code in a "codeturtles-own" variable called "code".
The average starting code length will be determined by a slider, as
will the size of the initial population. Again, I have not yet
decided the best way to represent this code. One natural way
would be to represent the code as a flat list of statements.
The preferable (and more ambitious) method is to represent code as
parse trees (I'm hoping to do this by using nested lists to represent
the trees in NetLogo). Although there has been some work with
genetic programming where the programs are encoded linearly (in
assembly languages, for one), I believe that the best empirical
results have been achieved with the use of tree structures.
(Side note: LISP-like languages are particularly well suited for
genetic programming because of how easily they may be represented as
trees...) In any case, there are quite a few difficulties to be
dealt with here -- such as how to represent important control
structures like conditionals and loops.
Generation Step
Phase:
Each codeturtle will, during time step t, run the code
that it is storing. This can be accomplished through the "run"
primitive in NetLogo ("runresult" may also prove useful).
Then the fitness for this turtle will be computed. I have not
yet decided whether it would be better to have all the turtles in the
generation run simultaneously or separately. Traditionally in
genetic programming, the programs are each run against the given
problem in isolation from each other. However, with NetLogo it
is equally doable to have the codeturtles run their programs
concurrently, even in some sort of competition with each other if the
problem we are trying to solve can be formulated in this way.
Another question is what to display to the user. Although it
might be educational to show each step of the process, there is a
difficulty of time here. That is to say, in order to get
effective results from genetic programming, a large population of
codeturtles will need to be run for a large number of generations.
So it might be better to only show the "best-so-far" code
turtle from each generation. After all, many of the codeturtles
in each generation are going to fail horribly at the task they are
meant to perform, and although it may be informative to watch a few
failures, I am sure that it will quickly grow old.
Breeding
Phase:
Codeturtles will be selected from the population
randomly, with greater preference given to those with high fitness.
One of the genetic operations (copying, mutation, or crossover --
chosen randomly, weighted by the probability sliders) will be
performed on each chosen code-turtle, to yield a new generation of
turtles. Depending on how I manage to implement the code
structure each codeturtle owns, it may be that some invalid
statements will be created (for that matter, they may have been
created invalid in the original random-creation step). And even
if type checking for each command, reporter, and operator is properly
handled, other runtime errors such as division-by-zero may occur.
Rather than prevent this, the simplest approach is to wrap "carefully
[]" blocks around the "run" commands, and then either
1) disqualify the codeturtle for bad code, or 2) just ignore bad
commands and go on. I strongly favor the latter approach.
Although one might have some reservations about allowing codeturtles
which have invalid code to continue to keep living, consider the
biological evolutionary process that genetic programming seeks to
emulate. The interactions of DNA are considerably more fault
tolerant than parse-checker of the NetLogo interpreter.
Furthermore, as I recall, a large percentage of the human genome
isn't being "used" -- it's just sitting there, like a DNA
junkyard of interesting material. Consider our error-giving
NetLogo commands to likewise be information-holders, from which code
can be swapped in and out via crossover operations. After the
new generation has been filled with codeturtles, the old generation
will pass away. The simulations will run again with the new
generation, the fitness for each computed, etc, and the cycle will
continue...
Interface:
The "view", of
course, shows codeturtles run through the simulation.
Fitness
monitor: shows the fitness of the best fit codeturtle so
far.
Time step monitor: shows the number of the current time
step
Fitness plot: plots the best-so-far fitness, and the
average fitness over all code turtles for each generation.
Sliders:
population size, program length
copying
probability, mutation probability
(let the crossover
probability = 1 - copying prob. - mutation prob.)
Buttons:
Setup, Go (forever), Step (one generation)
+ other controls I'm
sure I will think of later
+ any environmental controls for the
particular problem model
Rationale:
There are
several good things about using NetLogo to model genetic
programming. Primarily, NetLogo provides a configurable visual
environment for experiencing the process of genetic programming in a
much more hands-on way than would be possible with more traditional
languages such as Lisp, Java or C. The use of a multi-agent
environment also makes it easy handle collections of agents acting
and interacting, each with different sets of rules.
Also,
successful applications of genetic programming often require
tinkering, and NetLogo is a tinkerer's playground. The
effectiveness of the genetic programming algorithm depends on good
choices for functions and terminals, the fitness function, the size
of the population, the starting program length, and the probabilities
for crossover versus copying versus mutation. The functions and
terminals will hopefully be modifiable in the source code without too
much difficulty. The fitness function should be easy to change
in the source code too, but even better might be to have a Chooser
control with several choices for fitness functions for a given
model. The best tinkering, however, is with with the population
size, program length, and genetic operation probabilities since they
may be implemented naturally as sliders. These also are
particularly well suited for BehaviorSpace analysis, to determine the
effectiveness of various settings. BehaviorSpace could also be
used to test running the genetic programming algorithm for different
numbers of generations, to see what sort of improvement in results is
gained.
Also, the "run" primitive which allows a
string to be interpreted as code is a useful feature of the NetLogo
language. This makes it possible to create a NetLogo program
that creates NetLogo programs (or at least NetLogo code fragments).
Two Models:
I have tried to choose two substantially different
applications of genetic programming. The goal of the first
model is to solve a well-defined, algorithmic problem, by measuring
the performance of each member of the population in isolation.
The goal of the second model is to solve a fuzzier problem, where the
fitness of each individual is determined by simultaneously competing
with other members of the generation.
I. The Maze
Marchers
Overview: Use genetic programming to develop a
strategy for finding the goal state of a maze. This is a
classic problem in artificial intelligence, for which there is the
well known "right hand rule" solution. I hope that
genetic programming will find either this strategy, or some other
strategy that guarantees finding the maze exit.
Considerations:
I could use a few prebuilt mazes, but then agents might come up with
strategies that just work well on those given mazes. So I may
want to design a random maze generator.
Implementation:
Patches will serve as blocks, being either wall or empty.
Agents will not be allowed to move into wall patches.
Fitness
function possibilities: Closest (Cartesian distance, or
maze-walking distance) to maze exit (at the end of run, or at any
point during the run)
II. The Greedy Grazers
Overview:
Creatures are in competition for grazing -- use genetic programming
to find movement strategies for them that help maximize their food
intake. This is a more open-ended problem, and it will be
interesting to see what strategies evolve.
Considerations:
Since I don't know much about it, and can't intuitively see what
solutions will come up, it is entirely possible that the best
strategy will be something rather boring, like "walk in a
straight line." Or it may be that most strategies will
perform equally well. So I may need to change the rules some
once I get there, to define a more interesting problem. Need to
control the amount of movement each codeturtle has. We can't
let one of them win, simply because it's using "forward 5"
instead of "forward 1". Maybe only let the turtles
decide on a heading, and fix their movement?
Implementation:
Set all patches green. Place all codeturtles of the given
generation randomly on the field. Let them go for X time, and
when they walk over a green patch, turn it black. Count how
many patches they ate.
Fitness function possibilities:
Amount of grass eaten. (Amount of grass eaten / distance moved?
)
I must apologize that this section on the models is
rather small and vague at present. I think I need to cement
some of the implementation for the framework for genetic programming
before I can nail down the models that will be built on top of it.
Also, it is difficult to know whether or not genetic programming will
do a good job of solving a given problem until you try it. It
would seem rather silly to present a genetic programming model which
entirely fails to find a solution, and if this is the case, then I
may switch to other models that lend themselves better to being
solved by genetic programming.
I would be most grateful to
hear any feedback, suggestions, criticisms, possible pitfalls, etc,
about this project idea.
Back to Forrest's NetLogo Main
Page.